

Since our previous post announcing CommonLID, a new community-built language identification benchmark, the project has continued to grow. We’ve been focusing on two areas: improving usability and spreading the word.
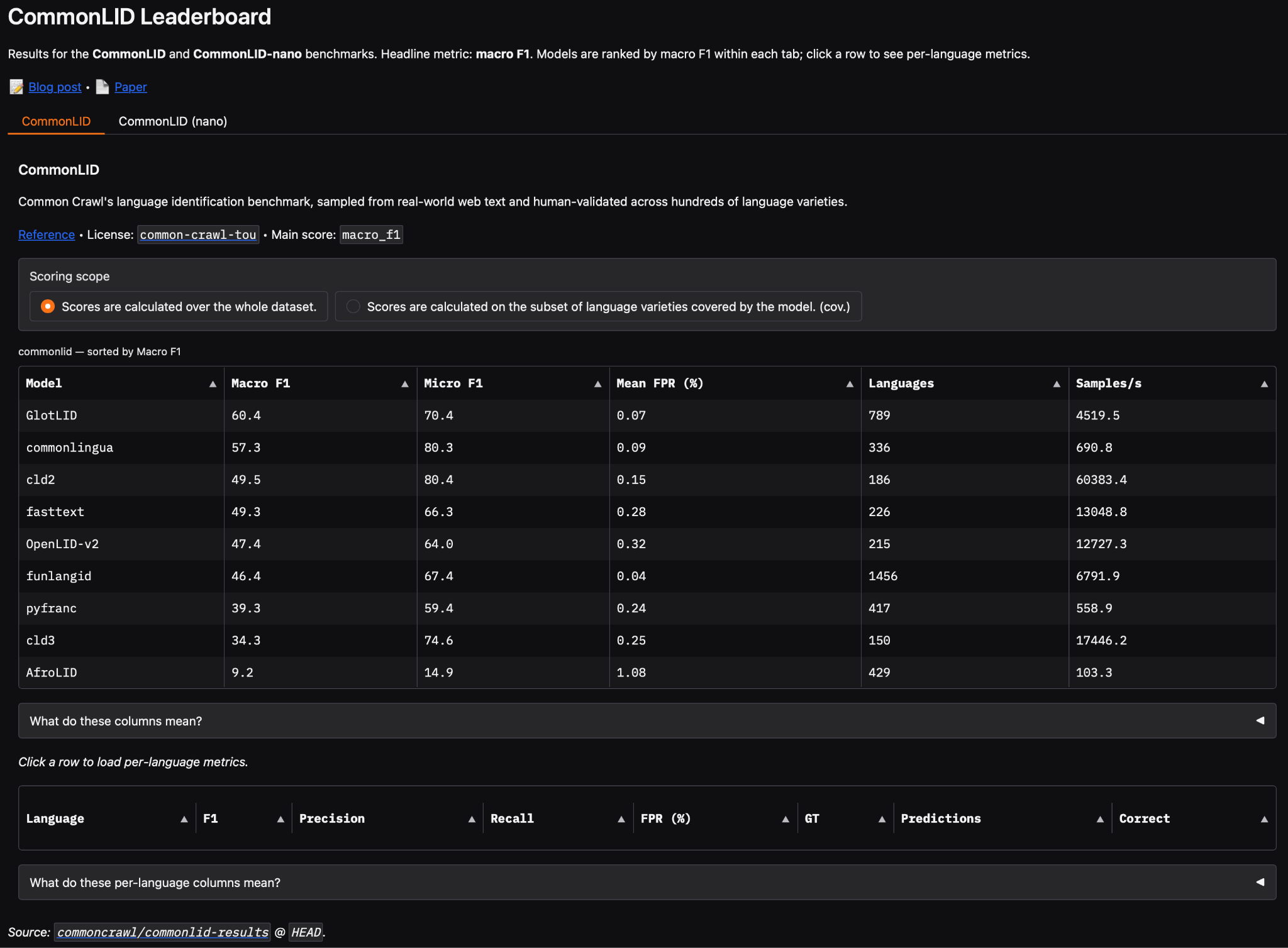
On the usability side, we now have a dedicated website for CommonLID: commonlid.org. You can find all the information and resources related to it here, and it’s where we’ll post any future updates. We’ve also made it easier to explore the state of the art for language identification through an interactive leaderboard. You can use it to compare performance on CommonLID by model and by language on a variety of metrics, all in the browser. If you’re looking to run your own evaluations, we’ve provided the source code and a PyPI package, which replicates the analysis in the paper and can be extended to other models and datasets.
As for spreading the word about CommonLID, in April we found out that the paper has been accepted to the main conference at ACL 2026 in San Diego! ACL is one of the top conferences in natural language processing, and we’re looking forward to connecting with the community there. We’ll be presenting our work on the 7th of July in poster session G. Aside from the paper, Common Crawl team members have also given multiple talks featuring CommonLID. These include presentations for EleutherAI, Cohere Labs (on YouTube), the Mozilla Data Collective and others.
For more information, check out the CommonLID CommonLID Paper and dataset, now available both on Hugging Face and through the Mozilla Data Collective. We want to keep improving this resource, so if you’d like to contribute, please raise an issue on the Hugging Face repo or get in touch via Discord.

.svg)
